Speech is the most natural way for humans to interact. After the invention of the computer, letting the machine "understand" the human language, understand the inner meaning of the language, and make the correct answer becomes the goal that people pursue. We all want to be like the intelligent and advanced robot assistants in science fiction movies, let them understand what you are talking about when communicating with people. Speech recognition technology has turned the once-dream of mankind into reality. Speech recognition is like a "machine's auditory system," which allows a machine to transform a speech signal into a corresponding text or command by recognizing and understanding.
Speech recognition technology, also known as Automated Speech Recognition AutomaTIc Speech RecogniTIon (ASR), aims to convert vocabulary content in human speech into computer readable input such as buttons, binary codes or sequences of characters. Speech recognition is like a "machine's auditory system", which allows a machine to convert a speech signal into a corresponding text or command by recognizing and understanding.
Speech recognition is a cross-disciplinary subject with a wide range of disciplines. It is closely related to the disciplines of acoustics, phonetics, linguistics, information theory, pattern recognition theory, and neurobiology. Speech recognition technology is gradually becoming a key technology in computer information processing technology.
Speech recognition is a cross-disciplinary subject with a wide range of disciplines. It is closely related to the disciplines of acoustics, phonetics, linguistics, information theory, pattern recognition theory, and neurobiology. Speech recognition technology is gradually becoming a key technology in computer information processing technology.
Development of speech recognition technology
The research of speech recognition technology began in the 1950s. In 1952, Bell Labs developed 10 isolated digital identification systems. Since the 1960s, Reddy et al. of Carnegie Mellon University in the United States have conducted continuous speech recognition research, but this period has been slow to develop. Pierce J of Bell Labs in 1969 even compared speech recognition to something that was impossible in recent years.
Beginning in the 1980s, the statistical model based on the hidden Markov model (HMM) method gradually occupied a dominant position in speech recognition research. The HMM model is a good description of the short-term stationary characteristics of speech signals, and integrates knowledge of acoustics, linguistics, syntax, etc. into a unified framework. Since then, the research and application of HMM has gradually become the mainstream. For example, the first "non-specific continuous speech recognition system" was the SPHINX system developed by Kai-Fu Lee, who was still studying at Carnegie Mellon University. The core framework is the GMM-HMM framework, in which GMM (Gaussian mixture model) Used to model the observation probability of speech, and HMM models the timing of speech.
In the late 1980s, the artificial neural network (AN), the predecessor of deep neural network (DNN), also became a direction of speech recognition research. However, this kind of shallow neural network has a general effect on speech recognition tasks, and its performance is not as good as the GMM-HMM model.
Beginning in the 1990s, speech recognition set off a small climax of the first research and industrial application, mainly due to the discriminative training criteria and model adaptive methods based on the GMM-HMM acoustic model. The HTK open source toolkit released by Cambridge during this period significantly reduced the threshold for speech recognition research. In the past 10 years, the research progress of speech recognition has been limited. The overall effect of the speech recognition system based on GMM-HMM framework is still far from practical level. The research and application of speech recognition has fallen into the bottleneck.
In 2006, Hinton proposed the use of a restricted Boltzmann machine (RBM) to initialize the nodes of the neural network, namely the deep belief network (DBN). DBN solves the problem that it is easy to fall into the local Zui in the process of deep neural network training. Since then, the tide of deep learning has been officially opened.
In 2009, Hinton and his student Mohamed D applied DBN to speech recognition acoustic modeling and succeeded in a small vocabulary continuous speech recognition database such as TIMIT.
In 2011, DNN succeeded in large-vocabulary continuous speech recognition, and the speech recognition effect achieved the biggest breakthrough in the past 10 years. Since then, the modeling method based on deep neural network has officially replaced GMM-HMM and has become the mainstream speech recognition modeling method.
Basic principles of speech recognition
The so-called speech recognition is to convert a speech signal into corresponding text information. The system mainly includes feature extraction, acoustic model, language model and dictionary and decoding. In order to extract features more effectively, it is also necessary to collect the information. The sound signal is subjected to pre-processing such as filtering and framing, and the signal to be analyzed is extracted from the original signal; after that, the feature extraction work converts the sound signal from the time domain to the frequency domain to provide an appropriate feature vector for the acoustic model; In the acoustic model, the score of each feature vector on the acoustic feature is calculated according to the acoustic characteristics; and the language model calculates the probability that the sound signal corresponds to the possible phrase sequence according to the linguistic related theory; finally, according to the existing dictionary, the phrase The sequence is decoded to get the last possible text representation.
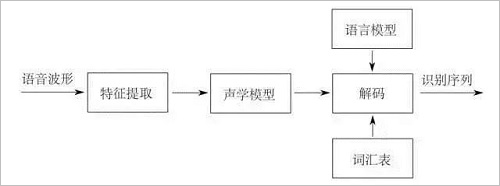
Acoustic signal preprocessing
As the premise and basis of speech recognition, the preprocessing process of speech signals is very important. In the final template matching, the characteristic parameters of the input speech signal are compared with the characteristic parameters in the template library. Therefore, only the characteristic parameters capable of characterizing the essential features of the speech signal can be obtained in the preprocessing stage. Matching is performed to perform speech recognition with high recognition rate.
Firstly, the sound signal needs to be filtered and sampled. This process is mainly to eliminate the interference of the frequency signal other than the human body sound and the 50Hz current frequency. The process generally uses a band pass filter to set the frequency of the upper and lower rings for filtering. The original discrete signal is quantized and processed; then the convergence of the high frequency and low frequency parts of the signal needs to be smoothed, so that the spectrum can be solved under the same SNR condition, which makes the analysis more convenient and fast; The operation is to make the signal in the original frequency domain change with time a short-term stationary characteristic, that is, the continuous signal is divided into independent frequency-domain stable parts by different lengths of the acquisition window for analysis, and the process mainly adopts pre-emphasis. Technology; finally, the endpoint detection work is required, that is, the start and end points of the input speech signal are correctly judged, mainly through short-time energy (the amplitude of the signal variation in the same frame) and the short-term average zero-crossing rate (in the same frame). The sampling signal passes through the number of zeros to make a rough determination.
Acoustic feature extraction
After the pre-processing of the signal is completed, what follows is the extremely critical feature extraction operation throughout the process. The recognition of the original waveform does not achieve a good recognition effect. The feature parameters extracted after the frequency domain transformation are used for identification, and the characteristic parameters that can be used for speech recognition must satisfy the following points:
1. Characteristic parameters can describe the fundamental characteristics of speech as much as possible;
2. Try to reduce the coupling between the parameter components and compress the data;
3. The process of calculating the characteristic parameters should be made simpler and the algorithm more efficient. Parameters such as pitch period and resonance peak can be used as characteristic parameters to characterize speech characteristics.
The most commonly used characteristic parameters of mainstream research institutions are: linear predictive cepstral coefficient (LPCC) and Mel cepstral coefficient (MFCC). The two characteristic parameters operate on the cepstrum domain on the cepstrum domain. The former uses the utterance model as the starting point and uses the LPC technique to find the cepstrum coefficient. The latter simulates the auditory model, taking the output of the speech through the filter bank model as an acoustic feature, and then transforming it using the discrete Fourier transform (DFT).
The so-called pitch period refers to the vibration period of the vocal cord vibration frequency (base frequency). Because it can effectively characterize the speech signal, the pitch period detection is a crucial research point since the initial speech recognition research; the so-called formant , refers to the region of energy in the speech signal, because it represents the physical characteristics of the channel, and is the main decision condition of the pronunciation sound quality, so it is also a very important feature parameter. In addition, many researchers have begun to apply some methods in deep learning to feature extraction, and have made rapid progress.
Acoustic model
The acoustic model is a very important component in the speech recognition system. The ability to distinguish different basic units is directly related to the quality of the recognition results. Speech recognition is essentially a process of pattern recognition, and the core of pattern recognition is the problem of classifiers and classification decisions.
Generally, the use of dynamic time warping (DTW) classifiers in isolated words and small and medium vocabulary recognition has a good recognition effect, and the recognition speed is fast and the system overhead is small, which is a very successful matching algorithm in speech recognition. However, in the case of large vocabulary and non-specific speech recognition, the DTW recognition effect will drop sharply. At this time, the use of Hidden Markov Model (HMM) for training recognition will be significantly improved, due to the traditional speech recognition. The continuous Gaussian mixture model GMM is generally used to characterize the state output density function, so it is also called the GMM-HMM framework.
At the same time, with the development of deep learning, the acoustic neural network is used to complete the acoustic modeling, forming a so-called DNN-HMM framework to replace the traditional GMM-HMM architecture, and has achieved good results in speech recognition.
Gaussian mixture model
For a random vector x, if its joint probability density function conforms to Equation 2-9, it is said to obey a Gaussian distribution and is denoted by x ∼ N(μ, Σ).
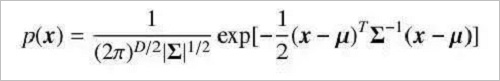
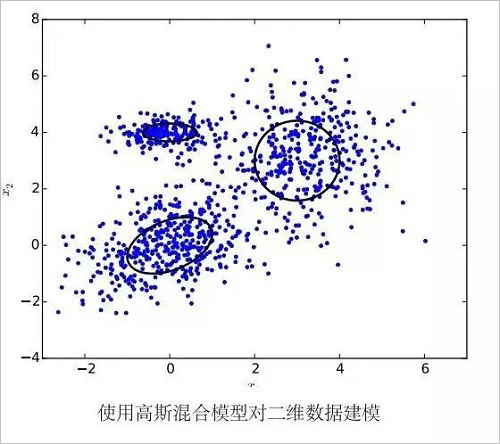
Where μ is the expectation of the distribution and Σ is the covariance matrix of the distribution. The Gaussian distribution has a strong ability to approximate real-world data and is easy to calculate, so it is widely used in various disciplines. However, there are still many types of data that are not well described by a Gaussian distribution. At this time we can use a mixed distribution of multiple Gaussian distributions to describe the data, with multiple components responsible for different potential data sources. At this point, the random variable conforms to the density function.
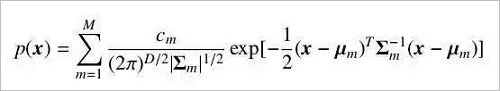
Where M is the number of components, usually determined by the size of the problem.
We refer to the model used by the data to obey the mixed Gaussian distribution as a Gaussian mixture model. Gaussian mixture models are widely used in the acoustic models of many speech recognition systems. Considering that the dimension of the vector is relatively large in speech recognition, we usually assume that the covariance matrix Σm in the mixed Gaussian distribution is a diagonal matrix. This greatly reduces the number of parameters and improves the efficiency of the calculation.
There are several advantages to using the Gaussian mixture model to model short-term eigenvectors. First, the Gaussian mixture model has strong modeling ability. As long as the total number of components is sufficient, the Gaussian mixture model can approximate a probability distribution with arbitrary precision. Function; in addition, the EM algorithm can easily converge the model on the training data. For the problems of calculation speed and over-fitting, people also studied the parameter-bound GMM and the subspace Gaussian mixture model (subspace GMM) to solve. In addition to using the EM algorithm for maximum likelihood estimation, we can also use the discriminative error function directly related to the word or phoneme error rate to train the Gaussian mixture model, which can greatly improve the system performance. Therefore, until the advent of techniques using deep neural networks in acoustic models, Gaussian mixture models have always been the only choice for short-term feature vector modeling.
However, the Gaussian mixture model also has a serious drawback: the Gaussian mixture model has very poor ability to model data on a nonlinear manifold near the vector space. For example, suppose some data is distributed on both sides of a sphere and is very close to the sphere. If we use a suitable classification model, we may need to distinguish the data on both sides of the sphere with only a few parameters. However, if Gaussian mixture models are used to describe their actual distribution, we need a lot of Gaussian distribution components to be sufficiently accurate to characterize. This drives us to look for a model that can more effectively use voice information for classification.
Hidden Markov Model
We now consider a discrete random sequence. If the transition probability conforms to the Markov property, and the immediate state is independent of the past state, it is called a Markov Chain. If the transition probability is independent of time, it is called a homogeneous Markov chain. The output of the Markov chain corresponds to a predefined state. For any given state, the output is observable and has no randomness. If we extend the output, each state of the Markov chain is output as a probability distribution function. In this case, the state of the Markov chain cannot be directly observed, and can only be inferred by other variables that are affected by the state change and that match the probability distribution. We call this model of modeling data with hidden Markov sequence hypotheses as hidden Markov models.
Corresponding to the speech recognition system, we use the hidden Markov model to characterize the internal sub-state changes of a phoneme to solve the problem of the correspondence between the feature sequence and multiple speech basic units.
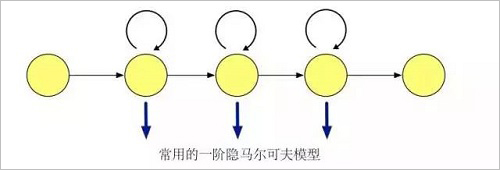
The use of hidden Markov models in speech recognition tasks requires the computation of the likelihood of the model over a segment of speech. In the training, we need to use the Baum-Welch algorithm [23] to learn the hidden Markov model parameters and perform Maximum Likelihood Estimation (MLE). The Baum-Welch algorithm is a special case of the EM (Expectation-Maximization) algorithm, which uses the pre- and post-term probability information to iteratively perform the E-steps of the conditional expectation and the M-steps that maximize the conditional expectation.
Language model
The language model is mainly to describe the habits of human language expression, focusing on the intrinsic relationship between words and words in the arrangement structure. In the process of speech recognition and decoding, the reference utterance dictionary and the inter-word transfer reference language model are transferred within the word. The good language model can not only improve the decoding efficiency, but also improve the recognition rate to some extent. The language model is divided into two types: rule model and statistical model. The statistical language model uses the method of probability and statistics to describe the internal statistical rules of language units. Its design is simple and practical and has achieved good results. It has been widely used in speech recognition and machines. Translation, emotional recognition and other fields.
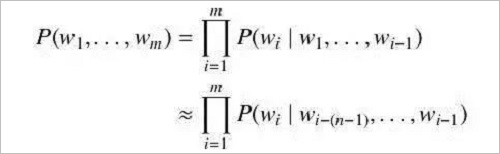
The simplest and most commonly used language model is the N-gram Language Model (N-gram LM). The N-ary language model assumes that currently given the above environment, the probability of the current word is only related to the first N-1 words. Then the probability P(w1, . . . , wm) of the word sequence w1, . . . , wm can be approximated as
In order to get the probability that each word in the formula is given above, we need a certain amount of the language text to estimate. The probability can be calculated directly using the ratio of the above words to all of the above pairs of words, ie
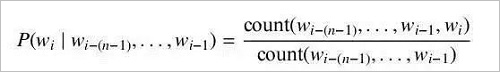
For word pairs that do not appear in the text, we need to use a smoothing method to approximate, such as Good-Turing estimates or Kneser-Ney smoothing.
Decoding and dictionary
The decoder is the core component of the recognition phase. The trained model decodes the speech to obtain the most probable word sequence, or generates a recognition grid based on the recognition intermediate result for subsequent component processing. The core algorithm of the decoder part is the dynamic programming algorithm Viterbi. Since the decoding space is very large, we usually use token passing methods that limit the search width in practical applications.
Traditional decoders dynamically generate decode graphs, such as HVite and HDecode in the well-known speech recognition tool HTK (HMM Tool Kit). Such an implementation has a small memory footprint, but considering the complexity of each component, the entire system is cumbersome, and it is inconvenient and efficient to combine the language model and the acoustic model, and it is more difficult to expand. The mainstream decoder implementation now uses a pre-generated Finite State Transducer (FST) as a preloaded static decoding map to some extent. Here we can construct the four parts of the language model (G), the vocabulary (L), the context-related information (C), and the hidden Markov model (H) as standard finite state converters, and then pass the standard finite state. The transformer operation combines them to construct a transformer from context-dependent phoneme substates to words. This implementation uses some extra memory space, but makes the decoder's instruction sequence more tidy, making the construction of an efficient decoder easier. At the same time, we can pre-optimize the pre-built finite state converter, merge and cut unnecessary parts, making the search space more reasonable.
How speech recognition technology works
First, we know that sound is actually a wave. Common mp3 formats are compressed and must be converted to uncompressed pure waveform files, such as Windows PCM files, also known as wav files. In addition to a file header stored in the wav file, it is a point of the sound waveform. The figure below is an example of a waveform.

In the figure, each frame has a length of 25 milliseconds with an overlap of 25-10 = 15 milliseconds between every two frames. We call it a frame length of 25ms and a frame shift of 10ms.
After framing, the voice becomes a lot of small segments. However, the waveform has almost no descriptive power in the time domain, so the waveform must be transformed. A common transformation method is to extract the MFCC features, and according to the physiological characteristics of the human ear, turn each frame waveform into a multi-dimensional vector, which can be simply understood as the vector containing the content information of the frame speech. This process is called acoustic feature extraction.
At this point, the sound becomes a 12-line (assuming the acoustic feature is 12-dimensional), a matrix of N columns, called the observation sequence, where N is the total number of frames. The observation sequence is shown in the figure below. In the figure, each frame is represented by a 12-dimensional vector. The color depth of the color block indicates the size of the vector value.
Next, we will introduce how to turn this matrix into text. First introduce two concepts:
Phoneme: The pronunciation of a word consists of phonemes. For English, a commonly used phoneme set is a set of 39 phonemes composed by Carnegie Mellon University. Chinese generally uses all initials and finals as phoneme sets. In addition, Chinese recognition is also divided into a tonelessness, which is not detailed.
Status: This is understood to be a more detailed phone unit than a phoneme. Usually a phoneme is divided into 3 states.
How does speech recognition work? In fact, it is not mysterious at all, nothing more than:
The first step is to identify the frame as a state.
The second step is to combine the states into phonemes.
The third step is to combine the phonemes into words.
As shown below:
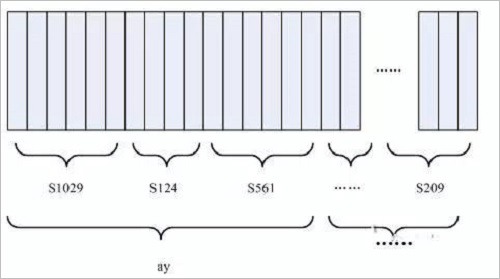
In the figure, each small vertical bar represents one frame, and several frame speeches correspond to one state, and each three states are combined into one phoneme, and several phonemes are combined into one word. In other words, as long as you know which state each voice corresponds to, the result of voice recognition comes out.
Which state does each phoneme correspond to? There is an easy way to think about which state has the highest probability of a frame, and which state the frame belongs to. For example, in the following diagram, the conditional probability of this frame is the largest in state S3, so it is guessed that this frame belongs to state S3.
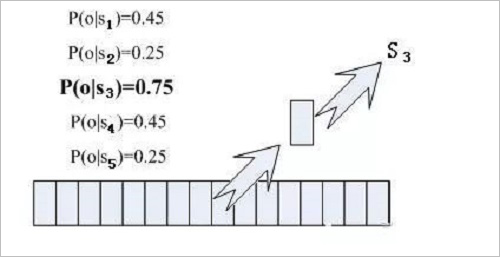
Where do the probabilities used are read? There is something called an "acoustic model" in which there are a lot of parameters, and through these parameters, you can know the probability of the frame and state. The method of obtaining this large number of parameters is called "training" and requires a huge amount of voice data.
But there is a problem with this: each frame will get a status number, and finally the entire voice will get a bunch of state numbers, the status numbers between the two adjacent frames are basically the same. Suppose the voice has 1000 frames, each frame corresponds to 1 state, and every 3 states are combined into one phoneme, then it will probably be combined into 300 phonemes, but this voice does not have so many phonemes at all. If you do this, the resulting status numbers may not be combined into phonemes at all. In fact, the state of adjacent frames should be mostly the same, because each frame is short.
A common way to solve this problem is to use the Hidden Markov Model (HMM). This thing sounds like a very deep look, in fact it is very simple to use:
The first step is to build a state network.
The second step is to find the path that best matches the sound from the state network.
This limits the results to a pre-set network, avoiding the problems just mentioned, and of course, it also brings a limitation. For example, the network you set only contains "days sunny" and "today rain". The state path of the sentence, then no matter what you say, the result of the recognition must be one of the two sentences.
So if you want to recognize any text? Make this network big enough to include any text path. But the bigger the network, the harder it is to achieve better recognition accuracy. Therefore, according to the needs of the actual task, the network size and structure should be reasonably selected.
Building a state network is a word-level network that is developed into a phoneme network and then expanded into a state network. The speech recognition process is actually searching for a good path in the state network. The probability that the voice corresponds to this path is the largest. This is called “decodingâ€. The path search algorithm is a dynamic plan pruning algorithm called Viterbi algorithm for finding the global zui optimal path.

The cumulative probability mentioned here consists of three parts, namely:
Probability of observation: probability of each frame and each state
Transition Probability: The probability that each state will transition to itself or to the next state
Language probability: probability obtained according to the law of linguistic statistics
Among them, the first two probabilities are obtained from the acoustic model, and the last probability is obtained from the language model. The language model is trained using a large amount of text, and can use the statistical laws of a language itself to help improve the recognition accuracy. The language model is very important. If you don't use the language model, when the state network is large, the results are basically a mess.
This basically completes the speech recognition process, which is how speech recognition technology works.
Voice recognition technology workflow
In general, a complete speech recognition system is divided into 7 steps:
1. Analyze and process the voice signal to remove redundant information.
2. Extract key information that affects speech recognition and feature information that expresses the meaning of the language.
3. Close the feature information and identify the words with the smallest unit.
4. Identify words according to their respective grammars in different languages.
5, the front and back meaning as an auxiliary recognition condition, is conducive to analysis and identification.
6. According to semantic analysis, divide the key information into paragraphs, take out the recognized words and connect them, and adjust the sentence composition according to the meaning of the sentence.
7. Combine the semantics, carefully analyze the relationship between the contexts, and make appropriate corrections to the statements currently being processed.
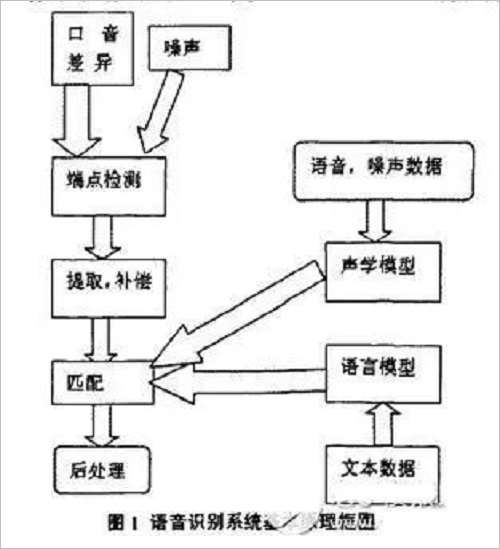
There are three points in the principle of speech recognition:
1. The encoding of the language information in the speech signal is performed according to the time variation of the amplitude spectrum;
2. Since the speech is readable, that is, the acoustic signal can be represented by a plurality of distinctive, discrete symbols without considering the information content conveyed by the speaker;
3. The interaction of speech is a cognitive process, so it must not be separated from the grammar, semantics and specification of terms.
Pre-processing, which includes sampling the speech signal, overcoming the aliasing filtering, removing some of the differences in the pronunciation of the individual and the noise caused by the environment, in addition to the selection of the speech recognition basic unit and the endpoint detection problem. Repeated training is to remove the redundant information from the original speech signal samples by allowing the speaker to repeat the speech multiple times before the recognition, retain the key information, and then sort the data according to certain rules to form a pattern library. Furthermore, pattern matching is the core part of the entire speech recognition system. It is based on certain rules and the similarity between the input characteristics and the inventory model, and then the meaning of the input speech.
The front-end processing first processes the original speech signal and then extracts the features to eliminate the influence of noise and different speaker's pronunciation differences, so that the processed signal can more fully reflect the essential feature extraction of the speech, eliminating noise and different The influence of the speaker's pronunciation difference makes the processed signal more fully reflect the essential features of the voice.
Aac Autoclave,Concrete Block Autoclave,Concrete Brick Autoclave,Autoclaved Aerated Concrete Brick Autoclave
JIANGSU OLYMSPAN THERMAL ENERGY EQUIPMENT CO.,LTD , https://www.compositesautoclave.com